

Las trampas del análisis cuantitativo
Un breve repaso a los sesgos más comunes en la toma de decisiones basadas en datos y cómo superarlos para crear productos que resuelvan problemas reales.


En la era de la toma de decisiones basada en datos, es cada vez más común utilizar información cuantitativa para guiar el desarrollo de productos. Sin embargo, aunque es tentador creer que más datos siempre conducirán a mejores decisiones, el análisis cuantitativo tiene sus limitaciones si no se comprende adecuadamente el contexto de los datos y no estamos alerta los sesgos típicos de la naturaleza humana.
Hace unas semanas escribí sobre los límites del espacio de la solución y cómo ejercicios como el opportunity mapping pueden ayudar a encontrar soluciones que realmente resuelvan los problemas de nuestros usuarios. Para que un ejercicio como este sea efectivo, es fundamental abordarlo con una mentalidad abierta y libre de ideas preconcebidas. Si ya llegamos con una solución en mente, no importa cuántos datos consultemos, siempre encontraremos las correlaciones necesarias para justificar la prioridad de nuestra solución favorita que requiere usar Kubernetes e IA.

Entonces, ¿usamos los datos para informar nuestras decisiones o para justificarlas a posteriori?
Démosle un repaso a algunos sesgos y malas prácticas a la hora de analizar datos para informar decisiones.
Tortuta de datos
¿Puedes creer que el número de avistamientos de ovnis en Missouri casi se correlaciona perfectamente con el consumo de petróleo en Kuwait? ¿Casualidad? ¿O es que los ovnis abastecen sus naves con el abundante petróleo de Kuwait antes de despegar?

Otro ejemplo curioso: hay una fuerte correlación entre los accidentes de avión y las búsquedas en Google de «cómo curar una resaca» ¿Coinciden estos accidentes aéreos con la tendencia en el consumo de alcohol? ¿Se caen los aviones porque se consume más alcohol o se consume más alcohol porque se caen más aviones?

Puedes encontrar miles de ejemplos de correlaciones interesantes como estos en la web de Tyler Vigen. Tyler explica cómo se pueden identificar estas correlaciones engañosas en grandes conjuntos de datos al realizar un «data dredging» o minería de datos sin una hipótesis previa:
Data dredging (dragado de datos): Tengo 25,237 variables en mi base de datos y comparo todas entre sí para encontrar coincidencias al azar, lo que implica 636,906,169 cálculos de correlación. Esto se llama «data dredging» y es un enfoque peligroso, ya que cualquier conjunto de datos lo suficientemente grande producirá correlaciones fuertes completamente al azar.
Falta de conexión causal: Es probable que no haya una conexión directa entre estas variables, a pesar de lo que pueda parecer. Esto se complica porque usé «Años» como la variable base, y muchas cosas ocurren en un año que no están relacionadas entre sí. La mayoría de los estudios usarían «una persona» en lugar de «un año» como la entidad estudiada.
Observaciones no independientes: En muchas variables, los años secuenciales no son independientes entre sí. Si una población de personas está haciendo algo continuamente todos los días, no es probable que cambien de repente el 1 de enero. Un cálculo simple de valor p no considera esto, por lo que matemáticamente parece menos probable de lo que realmente es.
Valores atípicos extravagantes: Hay «valores atípicos» o «outliers» en estos datos que destacan en el diagrama de dispersión. Intencionalmente manejé mal estos valores atípicos, lo que hace que la correlación parezca mucho más fuerte de lo que realmente es.
Ponte en el lugar de un producto como Netflix, que maneja un gran volumen de datos sobre los hábitos de visualización de millones de usuarios, es fácil que el equipo de producto, consciente o inconscientemente, busque justificar decisiones ya tomadas. Supongamos que tras un rediseño notan un cambio en la tendencia de consumo; podrían atribuirlo directamente a la reorganización de las categorías de contenido, sin considerar otros factores como el lanzamiento de una serie popular o cambios estacionales en el comportamiento de los usuarios.
Efecto de mirar en otra parte
Cuando se examina un gran conjunto de datos sin una hipótesis específica, aumenta la probabilidad de obtener falsos positivos. Sin una hipótesis clara antes de realizar el análisis de datos, corremos el riesgo de encontrar resultados espurios, un fenómeno también conocido como el «efecto de mirar en otra parte».

El matemático George Spencer-Brown, escribió que en una serie aleatoria de 10^1M ceros y unos deberías esperar al menos 10 subsecuencias no coincidentes de un millón de ceros consecutivos. De ahí que cuando los datos son abundantes, si buscas un patrón, es muy probable que lo encuentres. Como por ejemplo la imagen de la luna que al hacer zoom reveló la presencia de un rostro.

O el rostro capturado en la superficie de Marte por la misión Viking 1 en 1976.

Imagina que eres Amazon, con millones de transacciones diarias en su marketplace, y te pones a analizar datos sin una hipótesis concreta. Podrías encontrar una correlación entre la venta de ciertos productos en un día particular y otros eventos no relacionados, como un cambio en el clima o una campaña publicitaria en otro país.
Recordaréis el caso del aumento de comentarios negativos de las velas perfumadas durante la pandemia del COVID-19.
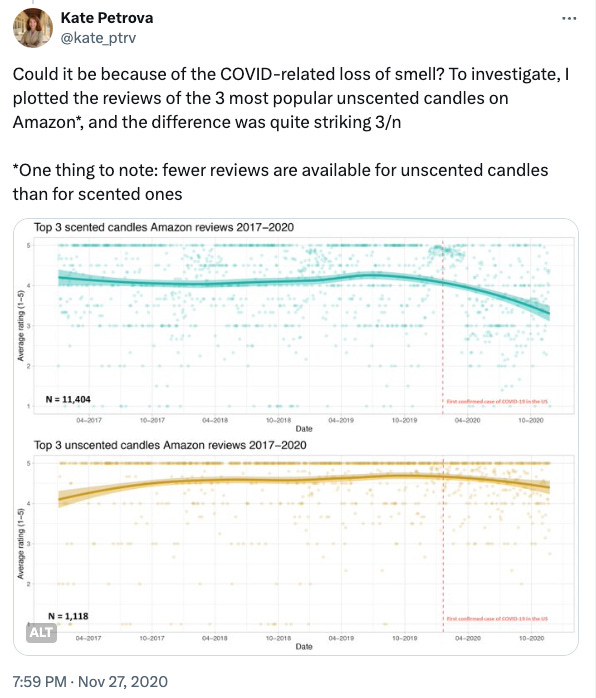
Sin una hipótesis clara, podrías malinterpretar estos patrones como señales de que deberías ajustar tu estrategia de marketing o inventario, cuando en realidad se trata de coincidencias sin relevancia para tu negocio.
Sesgo de confirmación
Estos son ejemplos del «sesgo de confirmación», la tendencia a favorecer, buscar, interpretar y recordar la información que confirma las propias creencias o hipótesis. Caemos en este sesgo cuando recordamos información de manera selectiva, o cuando la interpretamos sesgadamente como los ejemplos anteriores.
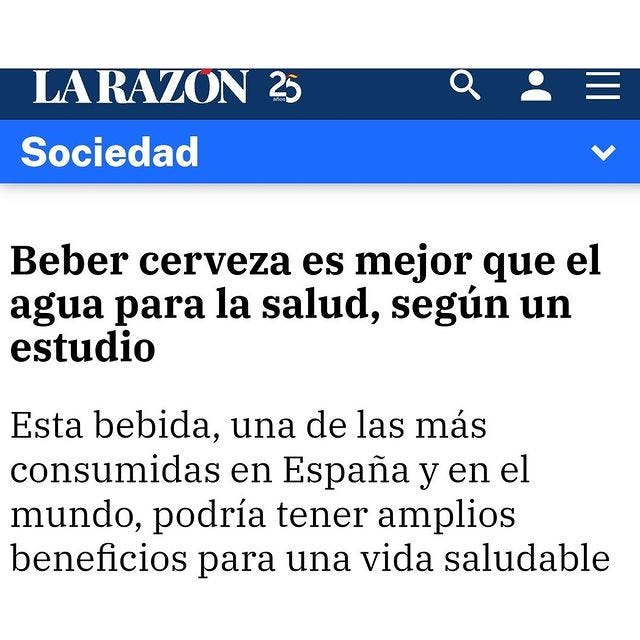
Hoy en día puedes encontrar estudios que parecen confirmar casi cualquier afirmación. ¿Hacen 45ºC en Córdoba, te gusta la cerveza pero no quieres sentirte culpable? Aquí tienes el titular perfecto: «La cerveza es mejor que el agua para la salud».
Este efecto es más fuerte cuando hay creencias firmemente enraizadas, como cuando vamos a un «opportunity mapping» enamorado de la solución que teníamos prevista y ya hemos visto que es relativamente sencillo justificar prácticamente cualquier cosa con un «análisis a posteriori».
Si torturas lo suficiente a tus datos, éstos te confesarán lo que quieras
— Ronald H. Coase (Premio Nobel de Economía, 1991)
Esto puede llevar a tomar decisiones de producto erróneas, basadas en patrones espurios, que resulten en inversiones en funcionalidades o mercados equivocados.
Correlación no implica causalidad y la regresión a la media
Los estudios científicos están plagados de errores como los que provoca Tyler en sus correlaciones. Aún aquellos realizados con el mayor rigor, pueden ser fácilmente sacados de contexto.
La falacia lógica de confundir correlación con causalidad ocurre cuando interpretamos erróneamente que una correlación (cuando dos variables se mueven juntas o están relacionadas) implica que una variable causa la otra. En otras palabras, vemos que dos cosas suceden al mismo tiempo o en paralelo, y asumimos incorrectamente que una es la causa de la otra, cuando en realidad pueden no estar relacionadas de manera causal.
Si a esto le sumamos nuestra tendencia a ignorar la «regresión a la media», los problemas se multiplican. Cuando una variable muestra un valor extremo (muy alto o muy bajo) en una medición, es probable que en futuras mediciones ese valor se acerque al promedio de la población.
Daniel Kahneman nos ofrece un buen ejemplo en Thinking, Fast and Slow de lo sencillo que es ignorar la regresión a la media:
Niños deprimidos tratados con una bebida energética mejoraron durante un período de tres meses.
Este titular de periódico me lo he inventado, pero el hecho del que informa es cierto: si durante un tiempo tratamos a un grupo de niños deprimidos con una bebida energética, mostrarán una mejora clínicamente significativa. También ocurre que los niños deprimidos que pasan algún tiempo haciendo el pino o abrazando a un gato durante veinte minutos al día mostrarán asimismo una mejora. La mayoría de los lectores de esta clase de titulares automáticamente deducirán que la bebida energética o abrazar a un gato producen una mejora, pero esta conclusión está totalmente injustificada. Los niños deprimidos constituyen un grupo extremo, pues están más deprimidos que la mayoría de los niños, y los grupos extremos regresan a la media con el tiempo. La correlación entre niveles de depresión y ocasiones sucesivas de prueba es menos que perfecta, y por eso habrá regresión a la media: los niños deprimidos estarán algo mejor con el tiempo incluso si no abrazan a los gatos ni toman Red Bull.
Para concluir que una bebida energética —o cualquier otro tratamiento— es efectivo, hemos de comparar un grupo de pacientes que reciben ese tratamiento con un «grupo de control» que no reciba tratamiento alguno (o, mejor, que reciba un placebo). Se espera que el grupo de control mejore solo por regresión, y la finalidad del experimento es determinar si los pacientes tratados mejoran más de lo que la regresión pueda explicar.
En ocasiones, las métricas proxy se eligen como indicadores de los outcomes de producto con la esperanza de que correlacionen con los objetivos de negocio finales. Por ejemplo, podrías utilizar el tiempo de uso de una aplicación como métrica proxy para la satisfacción del cliente. Sin embargo, si asumes que un mayor tiempo de uso causa una mayor satisfacción sin validar esta relación, podrías estar ignorando que otros factores, como la usabilidad o la calidad del contenido, son los que realmente impulsan la satisfacción del cliente, de ahí que sea crucial validar si existe una relación causal y no simplemente confiar en la correlación.
Además, debemos considerar los tiempos de reacción del entorno de tu producto. Tomar decisiones de manera apresurada, sin dar suficiente tiempo para observar los efectos, puede llevar a ignorar la regresión a la media y a malinterpretar los resultados. En Desarrollar productos, tan complejo como ducharse en el gym, discutí los peligros de no tener en cuenta los retrasos en los sistemas, lo que puede resultar en el «bandazo driven development».
Ley de los pequeños números
En entornos B2B, donde la base de usuarios es relativamente pequeña, es muy difícil demostrar que una correlación implique causalidad o evitar caer en la ignorancia de la regresión a la media.
Esto se debe a la «ley de los pequeños números», que describe la tendencia común a sobrestimar la representatividad de una muestra pequeña de datos. Este sesgo, popularizado por Kahneman, puede llevar a conclusiones incorrectas, ya que en muestras pequeñas es más probable que ocurran variaciones o anomalías que no serían tan comunes en una muestra más grande y representativa.
Por ejemplo, un pequeño grupo de usuarios que utiliza intensivamente una nueva funcionalidad puede hacer que parezca más popular de lo que realmente es.
Para evitar tomar decisiones basadas en datos no representativos, es fundamental complementar el análisis cuantitativo con técnicas de investigación cualitativa, como entrevistas en profundidad y prácticas como el continuous discovery. Estos enfoques permiten entender mejor las motivaciones y necesidades de los usuarios y mitigar el riesgo de tomar decisiones basadas en datos sesgados.
Heurístico de disponibilidad
El «heurístico de disponibilidad» es un atajo mental que usamos para tomar decisiones o hacer juicios basados en la facilidad con la que podemos recordar ejemplos o información relevante. En lugar de analizar toda la información disponible de manera objetiva, nuestras mentes tienden a darle más peso a la información que es más reciente, vívida o memorable, porque es más «disponible» en nuestra memoria.
Según Kahneman las «predicciones intuitivas» a menudo se basan en la disponibilidad de ejemplos recientes o llamativos, la representatividad (donde la gente juzga la probabilidad de un evento en función de qué tan similar es a otros casos conocidos), o el exceso de confianza en la exactitud de la propia intuición.
Es aquí donde una buena disciplina de análisis de datos nos puede ayudar, de lo contrario es fácil que nos enfoquemos demasiado en los ejemplos recientes o en las quejas más vocales de los usuarios. Esto puede llevar a priorizar problemas que son llamativos pero no representativos, desviando la atención de problemas más críticos que podrían estar afectando a una parte más amplia de la base de usuarios.
Aunque estas predicciones intuitivas pueden ser útiles en situaciones cotidianas, pueden ser engañosas en contextos más complejos o cuando se requiere una evaluación precisa y objetiva.
Sesgo de supervivencia
Al analizar los datos de usuarios activos, corremos el riesgo de ignorar los comportamientos de aquellos que abandonaron la plataforma. Por ejemplo, al interpretar datos de uso de una nueva funcionalidad, es fácil pasar por alto a los usuarios que dejaron de utilizar el producto, lo que podría llevar a una interpretación sesgada sobre el éxito de dicha funcionalidad.
El «sesgo de supervivencia» ocurre cuando se da más importancia a los datos de los “sobrevivientes” de un proceso, ignorando a aquellos que no lo hicieron. Es una forma de «sesgo de selección» que puede llevarnos a manipular los datos de manera que confirmen nuestras expectativas, otro tipo de tortura de datos.
En culturas donde se celebra únicamente la épica y el éxito, y apenas se presta atención a la oportunidad de aprender de los fracasos, es más fácil olvidar los escenarios fallidos al plantear nuevas soluciones. Esta falta de consideración puede resultar en decisiones mal informadas que no reflejan las realidades completas del producto y su mercado.
Falacia narrativa
En El cisne negro, Nassim Taleb introdujo el concepto de «falacia narrativa» para describir cómo las historias cuestionables sobre el pasado moldean nuestras percepciones del mundo y nuestras expectativas para el futuro. Estas falacias surgen inevitablemente de nuestro constante esfuerzo por darle sentido a la realidad. Las historias que la gente considera persuasivas tienden a ser simples, concretas y a atribuir mayor importancia al talento, la estupidez o las intenciones, en lugar de al azar. Además, se enfocan en unos pocos eventos llamativos que ocurrieron, ignorando muchas otras cosas que no sucedieron. Cualquier acontecimiento reciente y notable puede convertirse en el eje de una explicación causal, influenciado por el «heurístico de disponibilidad». Taleb sugiere que los seres humanos nos engañamos a menudo al construir narrativas frágiles sobre el pasado que asumimos como verdaderas.
La «falacia narrativa» también puede estar influenciada por el «sesgo de supervivencia», donde se destacan los casos de éxito, mientras se ignoran los fracasos o eventos menos visibles. Esto refuerza una visión distorsionada de la realidad que puede llevarnos a crear explicaciones convincentes pero incorrectas sobre por qué un producto tuvo éxito o fracasó, basándonos en anécdotas o en eventos recientes. Estas narrativas simplificadas pueden influir en decisiones futuras, centrándose en factores incorrectos y repitiendo errores pasados. Para evitar esto, es importante combinar las narrativas con un análisis de datos riguroso. Análisis de causa raíz profundos, utilizando prácticas como el modelo del iceberg, pueden ser mucho más efectivos.
Slow systems thinking con el modelo del iceberg

Ver el mundo como una sucesión de acontecimientos es increíblemente apasionante, y nunca deja de sorprendernos, porque esa visión del mundo no posee prácticamente ningún valor predictivo ni explicativo. Al igual que la punta de un iceberg que sobresale del agua, los sucesos son el aspecto más visible de un complejo mayor, pero no siempre son lo más impo…
Conclusiones
Cuanto más informadas sean nuestras decisiones, menos bandazos daremos. Esta es solo una pequeña muestra de los sesgos en los que podemos caer al tratar con datos. Con este breve repaso, he intentado resaltar la importancia de ser muy cuidadosos con los análisis cuantitativos. Las personas con perfiles de ingeniería tendemos a ser muy analíticas y apasionadas por los números, pero no debemos perder de vista a los actores de nuestro producto. Es esencial empatizar con sus necesidades y combinar los datos con un análisis cualitativo riguroso.
Como hemos visto, existen peligros en ambos extremos: tanto en manejar una gran cantidad de datos, como ocurre en Amazon, donde se puede encontrar prácticamente cualquier patrón a posteriori, como en trabajar con una muestra pequeña de clientes, donde establecer hipótesis conlleva el riesgo de confundir el azar con causalidad.
Enfoques como continuous discovery y desarrollo lean que permitan ciclos cortos de iteración son herramientas esenciales para experimentar en entornos de alta incertidumbre.
Finalmente, quiero defender el valor de la intuición. No todas las organizaciones cuentan con una cultura «data-driven» bien establecida. En esos casos, pretender que los datos te darán todas las respuestas, ignorando la intuición y la experiencia de quienes mejor entienden el mercado dentro de la organización, puede ser un grave error. La clave está en encontrar un equilibrio entre los datos y la intuición para tomar decisiones de producto más acertadas.
Lecturas recomendadas
El andar del borracho: Cómo el azar gobierna nuestras vidas — Leonard Mlodinow
Pensar rápido, pensar despacio — Daniel Kahneman
The Great Mental Models, Volume 1: General Thinking Concepts — Shane Parrish
The Great Mental Models, Volume 3: Systems and Mathematics — Shane Parrish
Por qué creemos en mierdas: Cómo nos engañamos a nosotros mismos — Ramón Nogueras
El cisne negro: El impacto de lo altamente improbable — Nassim Nicholas Taleb
La realidad no existe: Cómo entender el mundo cuando entiendes que no entiendes nada — Jaime Rodríguez de Santiago
Empathy-Driven Development: How Engineers Can Tap into This Critical Skill — Andrea Goulet
Continuous Discovery Habits: Discover Products that Create Customer Value and Business Value — Teresa Torres
Racionalidad: Qué es, por qué escasea y cómo promoverla — Steven Pinker
Spurious patterns and where to find them

{kind=link}