


La trampa de la adicción al parche

Artículo publicado originalmente en mi blog en noviembre de 2023. Estoy escribiendo una nueva entrega sobre una herramienta práctica para combatir esta trampa, así que lo rescato por si no lo has leído y te interesa echarle un vistazo mientras.

“las drogas ni tocarlas” — madre anónima
Una de las trampas en las que más caemos en nuestro día a día como desarrolladores es la de reaccionar a síntomas con soluciones que no curan de raíz el problema. Terminamos tropezándonos repetidamente con la misma situación y cuando queremos atacar la raíz del problema normalmente ya es demasiado tarde.
Suena a verdad de Perogrullo porque nos vienen a la cabeza ejemplos que pueden ser tan de sentido común como no descuidar la deuda técnica o intentar encontrar la causa raíz de un bug y solucionarla antes de dar por terminado el asunto con el hotfix.
Pero el entorno del desarrollo de producto es más complejo que eso y hay otros ejemplos no tan evidentes en los que caer no es tan difícil si no tenemos un enfoque sistémico.
Desplazamiento de la carga hacia la intervención
Ya intruduje las trampas y oportunidades de los sistemas en el primer post de esta serie.
Este arquetipo o trampa consiste en la aplicación de una solución sintomática rápida y fácil que solo alivia temporalmente el problema, y una solución fundamental que requiere más tiempo y recursos pero ofrece una solución a largo plazo.
El dilema radica en que emplear la solución sintomática puede inadvertidamente hacer más difícil implementar la solución fundamental, llevando a un ciclo vicioso de abordar solo los síntomas repetidamente en lugar de resolver el problema de raíz.
Este deterioro del sistema hace que cada vez dependamos de dosis más altas de esa solución temporal que termina convirtiéndose en una adicción de la que será muy difícil salir: drogas, subsidios, etc.
Escalar verticalmente como droga
Veamos un ejemplo real que he vivido en Audiense para entender la trampa desde el punto de vista de la dinámica de sistemas y al final del post veremos otros ejemplos de situaciones que encajan en este modelo.
Hace 6 o 7 años elegimos una tecnología de almacenamiento de datos para solucionar un caso de uso que necesitaba procesar queries de SQL muy complejas combinando cientos de millones de filas. Fue lo mejor que encontramos en ese momento y durante algún tiempo cumplió su función.
Con el tiempo, el número de clientes y uso de la funcionalidad que dependía de esta base de datos empezó a crecer, así como el número de filas y concurrencia que teníamos que manejar.
La solución que decidimos aplicar fue escalar verticalmente, es decir, aumentar las prestaciones del servidor de esa base de datos, pagando más. Cada vez que tocábamos techo, volvíamos a considerar si deberíamos invertir en cambiar la tecnología o seguir aumentando prestaciones. Como podíamos pagarlo y la operación de mantenimiento requería solo horas en comparación con una migración tecnológica que costaba meses, optamos por seguir escalando verticalmente.
El número de filas ya superaba los miles de millones y nuestras necesidades de prestaciones crecían a mayor ritmo que lo que dicta la Ley de Moore, por lo que empezábamos a rozar los límites del crecimiento de ese servidor.
En ese punto, la complejidad de las funcionalidades construidas encima de esa tecnología había crecido tanto que plantearnos migrar podría matar la empresa. Por suerte, AWS siguió sacando instancias cada vez más potentes y pudimos seguir enganchados a nuestra droga.
Modelemos este escenario con dinámica de sistemas
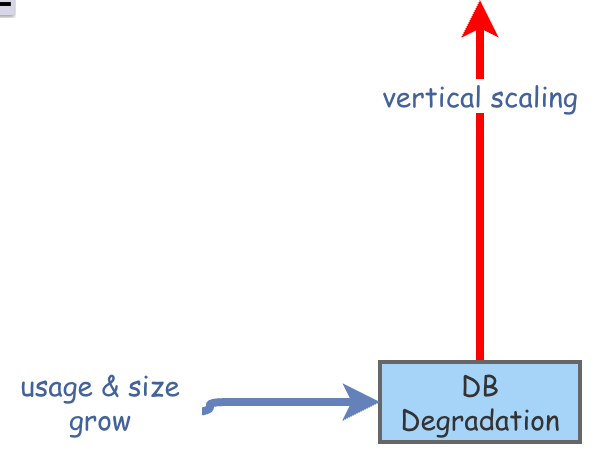
“DB Degradation” en el diagrama es el síntoma del problema. El rendimiento de la base de datos se va degradando con el crecimiento de la concurrencia de uso y el número de filas (“usage & size grow”).
“vertical scaling” es la solución sintomática que temporalmente mejora el rendimiento de la base de datos.
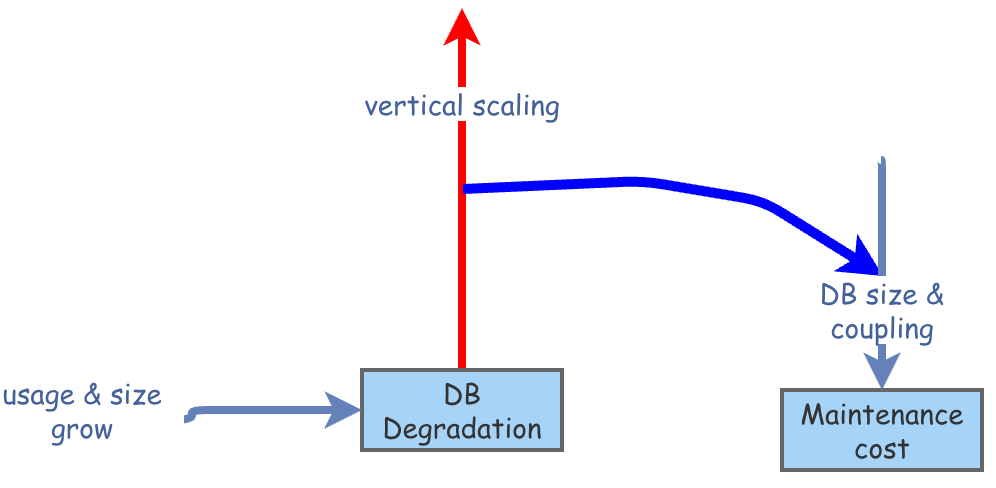
Mientras escalamos verticalmente, el crecimiento del tamaño de la base de datos y su integración con el producto hacen que cada vez sea más costoso hacer una migración a otra tecnología.
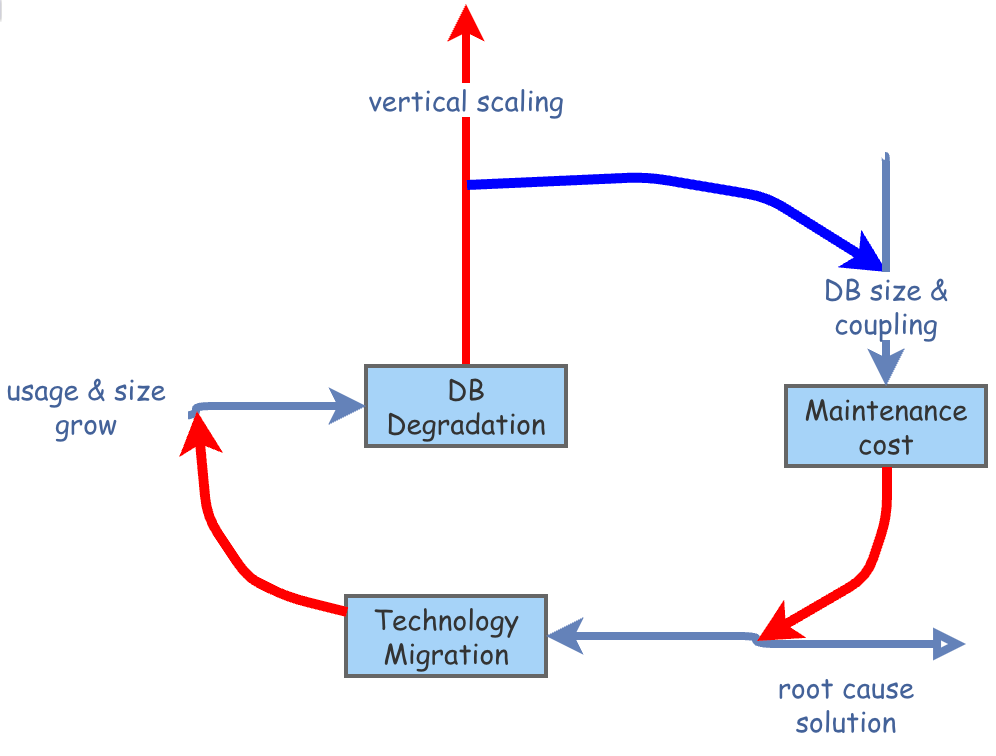
“Technology Migration” representa la solución fundamental para seguir creciendo sin depender del escalado vertical.
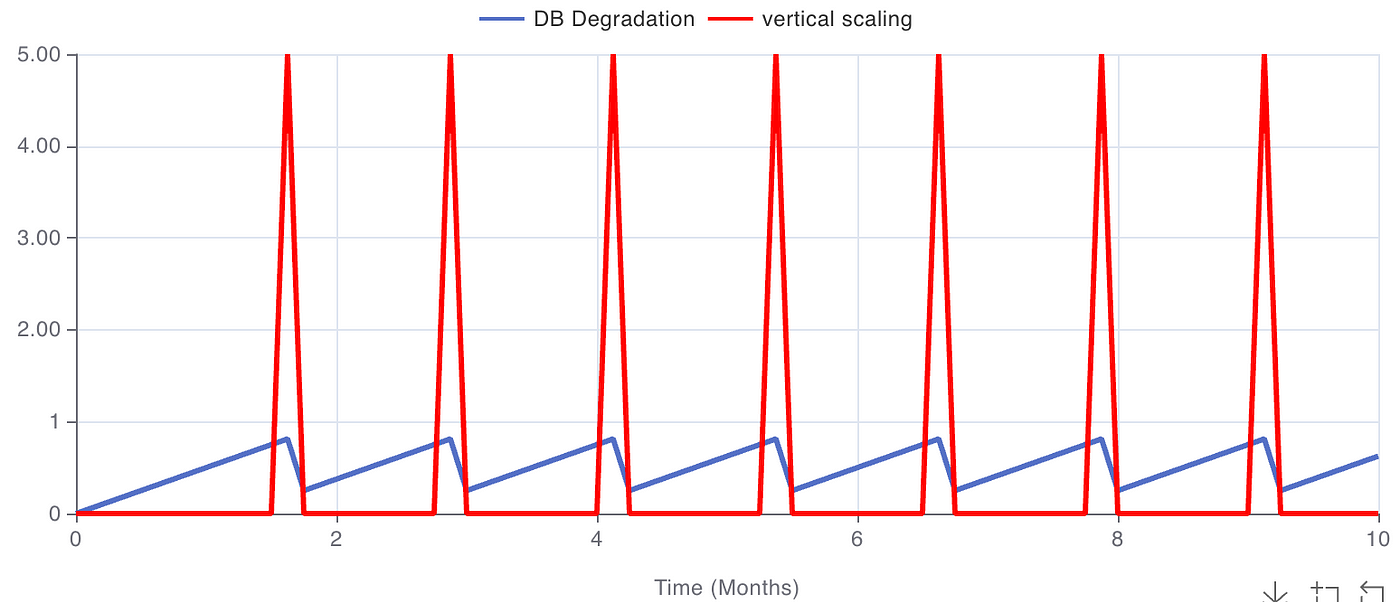
Como se ve en la gráfica de la simulación, mientras solo apliquemos la solución al síntoma (línea roja), el problema (línea azul) vuelve a aparecer una y otra vez.
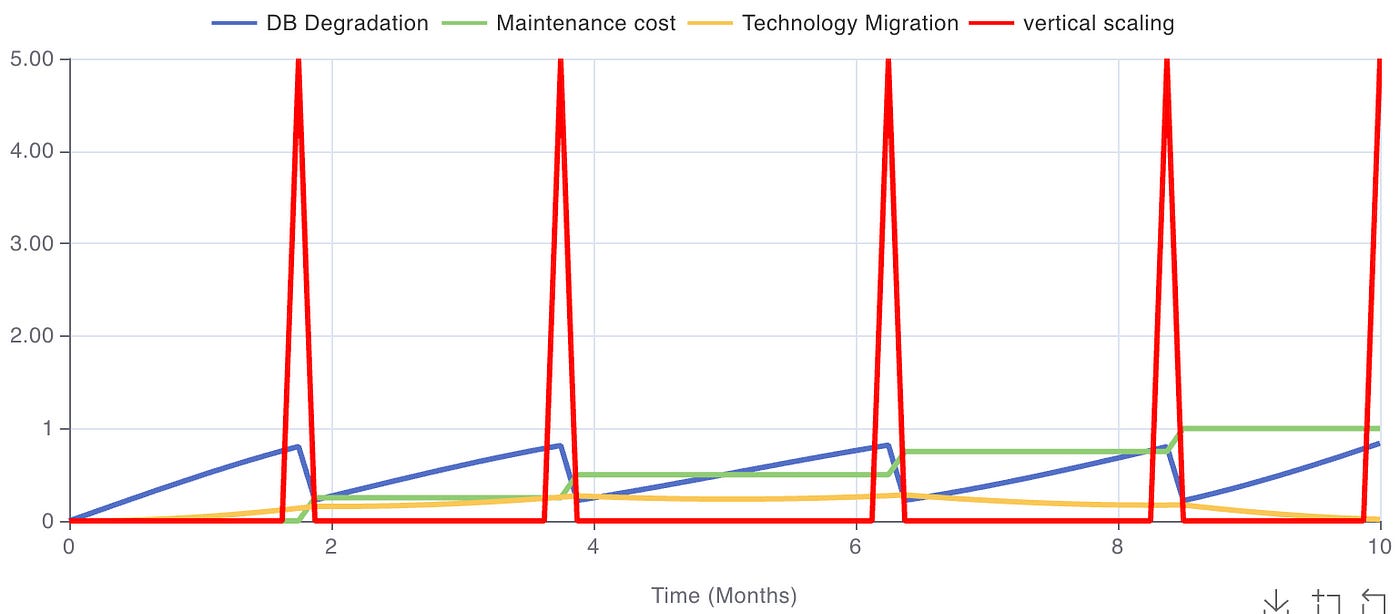
Para salir de esta trampa, tenemos que trabajar en la solución fundamental antes de que el coste de implementarla sea muy alto.
En el diagrama, vemos cómo el coste de mantenimiento (línea verde) va creciendo y la posibilidad de implementar la migración (línea amarilla) termina cayendo mientras sigue el ciclo de reaparición del problema (línea azul) y aplicación de parche (línea roja).
Concluyendo
Me gusta la analogía del bote con una fuga de Gene Bellinger, autor del modelo en el que me he inspirado para este post.
Aunque es crucial achicar el agua para evitar que el bote se hunda (solución sintomática), es igualmente importante reparar la fuga (solución fundamental) para prevenir problemas futuros. Continuar sacando agua sin arreglar la fuga solo retrasará la necesidad de una solución permanente y permitirá que la fuga se haga cada vez más grande.
Como ya había adelantado, hay muchos escenarios que aplican a este modelo. Una vez que entiendes este patrón, comienzas a verlo surgir en todas partes:
Tu software no escala: Aumentas la capacidad e inviertes en autoescalado, cuando la causa raíz podría estar en el comportamiento de los usuarios, que quizás se solucione con una mejor experiencia de usuario (UX).
Tienes que pagar más por un SaaS del que dependes: Entender a tiempo el modelo de precios del SaaS y los límites a los que te enfrentarás al crecer su uso puede ayudarte a tomar medidas para un uso más eficiente antes de que la única solución sea simplemente pagar más, ya que cambiar el patrón de uso a ese punto puede ser muy costoso.
Alto ratio de fallos en producción: Inviertes en equipos de QA en lugar de mejorar las prácticas del equipo. Una mejor inversión sería en pruebas automatizadas integradas desde el diseño del software, no solo al final del proceso. Tema que abordé en los posts sobre la trampa del testing coverage y la entropía del software.
Problemas de seguridad: Te enfrentas a muchos problemas de seguridad o necesitas pasar certificaciones o auditorías de clientes, lo que implica un gran esfuerzo. Idealmente, deberíamos integrar los principios de desarrollo seguro en nuestro flujo de desarrollo desde el principio, no solo al final, como promueve la mentalidad DevSecOps.
Baja eficiencia en tu flujo de desarrollo: Contratas más personal en lugar de invertir en mejorar sus flujos, la experiencia de desarrollo y su formación.
Alta rotación en el equipo: Intentas solucionarla aumentando los salarios en lugar de identificar y solucionar la causa real por la que se van, que generalmente no es solo por dinero.
Tu equipo se bloquea porque depende de ti: Intentas abarcarlo todo, leer todos los canales de Slack, aceptar todas las reuniones, en lugar de invertir en romper tus silos de conocimiento y delegar más. Cuanto más dilates esto y más crezca el equipo, menos tiempo tendrás para solucionarlo.
Podría continuar con muchos más ejemplos, pero creo que estos son suficientes para ilustrar claramente la idea. Os invito a compartir en los comentarios otros casos reales en los que hayáis reconocido haber caído en esta trampa.
Serie: las trampas de los sistemas complejos
Este post forma parte de una serie sobre las trampas de los sistemas complejos aplicadas al desarrollo de productos:
Elusión de las reglas y persecución del objetivo equivocado: La trampa del testing coverage.
Desplazamiento de la carga hacia la intervención: La trampa de la adicción al parche.
Deriva hacia el bajo rendimiento: La Trampa de la Erosión de Metas y el Síndrome de la Rana Hervida.
Tragedia de los recursos comunes: La tragedia del código compartido.
Exclusión competitiva o «el éxito que atrae el éxito»: La trampa del «rockstar developer». La exclusión competitiva y el efecto Pigmalión.
Aclaración: Las simulaciones presentadas en este artículo no pretenden tener rigor científico. Su propósito es ilustrar visualmente patrones que he observado en proyectos. Es más relevante considerar las tendencias y patrones de las gráficas que sus valores exactos.
Si has llegado hasta aquí y crees que esta perspectiva puede ayudar a otras personas a comprender el valor de los enfoques que listo, te agradecería que lo compartas. Además cualquier interacción con el artículo me da pistas de si estos temas son de interés 🙏🏼.